SchemaFusion Engine
A data virtualization and federation middleware implementing the EasyBDI 2.0 architecture for distributed query orchestration across heterogeneous data sources.
SchemaFusion Engine
A middleware implementation of the EasyBDI 2.0 architecture, focusing on Data Virtualization and Federation. SchemaFusion provides a headless interface for orchestrating distributed queries across heterogeneous data sources using Trino as the query engine.
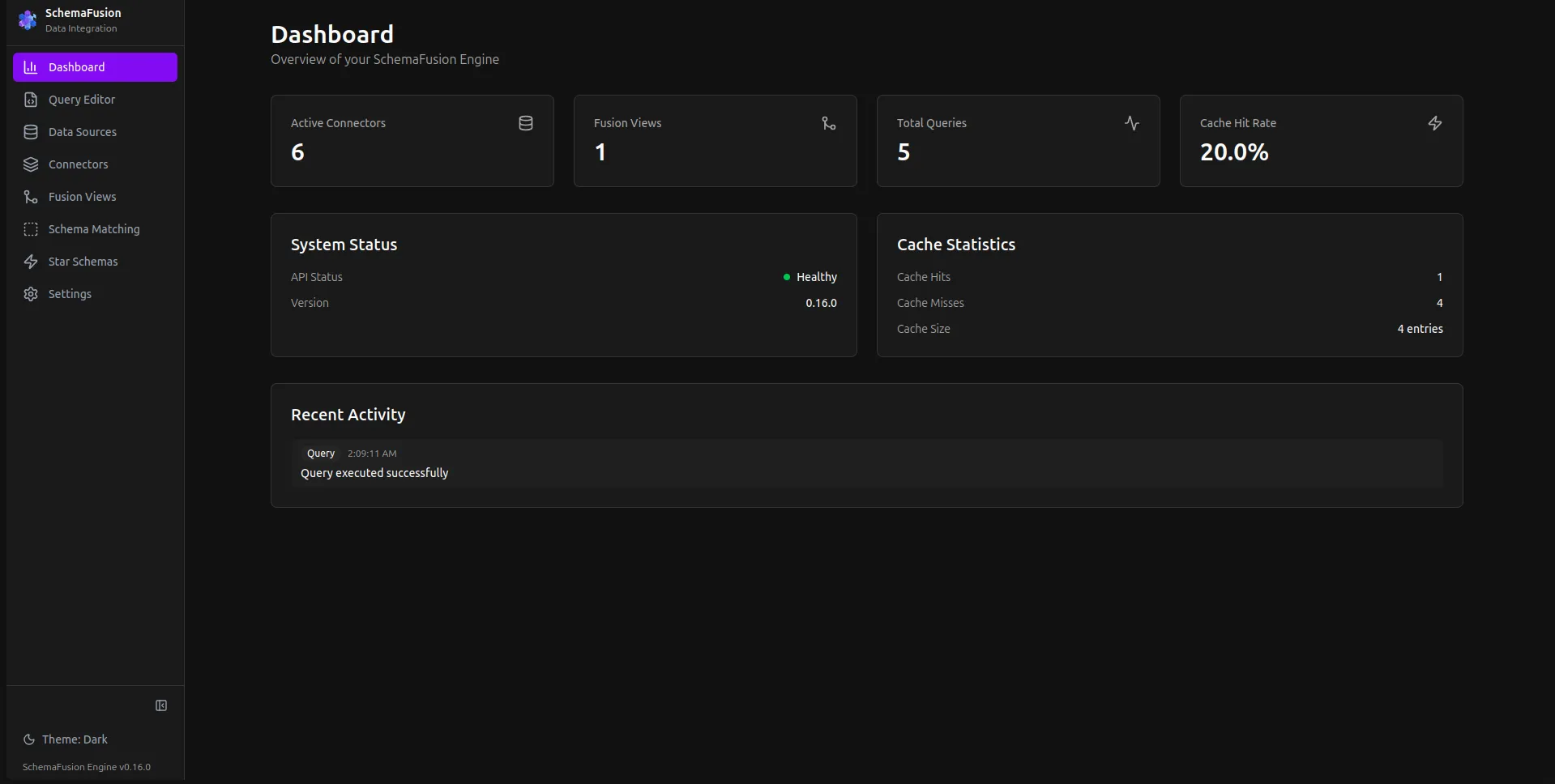
Overview
SchemaFusion acts as a middleware layer that federates queries across multiple data sources, virtualizes data access, and orchestrates query planning and execution. Built for the Distributed Systems course at University of Aveiro.
Key Features
Data Federation
- Query federation across PostgreSQL, MongoDB, CSV files, and Google Sheets
- Automatic schema discovery and matching
- Support for 3+ source fusion with JOIN and UNION operations
- Type coercion for heterogeneous data sources
Query Engine
- Distributed query processing with Trino
- Real-time query execution and optimization
- Caching layer with Redis for improved performance
- Query history and analytics
Schema Management
- Automatic column matching between tables
- Confidence scoring for schema mappings
- Star schema builder for data warehousing
- Dynamic view creation and management
Developer Experience
- RESTful API with FastAPI
- Interactive API documentation (Swagger/OpenAPI)
- CLI tool for configuration management
- Docker Compose orchestration for easy setup
- Comprehensive test suite with pytest
Architecture
The system consists of several integrated components orchestrating distributed queries across heterogeneous data sources:
graph LR
UI["`Frontend UI`"] --> Gateway
Gateway --> API["`FastAPI Middleware`"]
API --> Trino
Trino --> Postgres[("`PostgreSQL`")]
Trino --> Mongo[("`MongoDB`")]
Trino --> Kafka[["`Kafka`"]]
API --> Redis[("`Redis Cache`")]
Key Components:
- Trino (port 8080): Distributed query engine responsible for query execution and optimization.
- FastAPI Middleware (port 8000): Headless REST API interface serving as the primary control plane.
- Gateway (port 80): Single entrypoint reverse proxy.
- Redis (port 6379): High-performance caching layer for query results.
- Data Sources: PostgreSQL (Relational), MongoDB (NoSQL), Kafka (Streaming).
API Examples
Query Execution
POST /fusion/query
{
"query": "SELECT * FROM postgres.public.users LIMIT 10",
"catalog": "postgres",
"schema": "public",
"max_rows": 100
}Schema Matching
POST /fusion/match
{
"source_catalog": "postgres",
"source_schema": "public",
"source_table": "users",
"target_catalog": "mongo",
"target_schema": "testdb",
"target_table": "customers",
"threshold": 0.8
}Create Fusion View
POST /fusion/create-view
{
"view_name": "global_customers",
"source_a": {"catalog": "postgres", "schema": "public", "table": "users"},
"source_b": {"catalog": "mongo", "schema": "testdb", "table": "customers"},
"matches": [...],
"join_key_a": "id",
"join_key_b": "_id"
}Technical Highlights
- Polyglot Persistence: Seamless integration across SQL, NoSQL, and streaming data sources
- Type Safety: Python type hints throughout with MyPy validation
- Code Quality: Automated linting (Ruff), formatting (Black), and pre-commit hooks
- Testing: Comprehensive test coverage with pytest and coverage reporting
- Monitoring: Prometheus metrics, Grafana dashboards, and AlertManager setup
- Security: API key authentication, secure credential management
- Documentation: Extensive markdown documentation and architecture diagrams
Tech Stack
- Backend: Python 3.11+, FastAPI, Typer CLI
- Query Engine: Trino with multiple connectors
- Databases: PostgreSQL, MongoDB
- Streaming: Apache Kafka
- Caching: Redis
- Containerization: Docker, Docker Compose
- Frontend: React, TypeScript
- Testing: pytest, pytest-cov
- Code Quality: Ruff, Black, MyPy, pre-commit
Project Context
Developed as part of the Data Oriented Systems course (SOD) at University of Aveiro, this project demonstrates advanced concepts in:
- Distributed systems architecture
- Data integration and ETL processes
- Query optimization and execution
- Microservices design patterns
- API design and documentation
- DevOps practices
Results
The project successfully implements a production-ready data federation system capable of:
- Querying across 4+ different data source types
- Sub-second query execution for federated queries
- Automatic schema discovery and matching with 80%+ confidence
- Handling complex JOIN and UNION operations across heterogeneous sources